

Cómo usar IA en local en un portátil normal
Lo que ya puedes hacer con LM Studio en un Mac con 8 GB de RAM y dónde siguen estando los límites

👋 Hola, aquí Edgar Otero. Esta es mi newsletter semanal para que leas la IA con calma, elimines el ruido y te quedes con lo que de verdad es importante. Cada miércoles a las ☕️ 7:00 en tu correo.
Edición extra con guía práctica.
La IA local ya no es solo una curiosidad para gente más técnica. Hoy puedes montar un chatbot que funcione en tu propio ordenador en pocos minutos, con una interfaz normal y sin necesidad de tocar la terminal.
Lo interesante es que, incluso en un portátil modesto, la experiencia ya puede ser suficientemente buena para tareas sencillas de trabajo real: reformular textos, ordenar ideas, crear tablas o ayudarte a dar forma a borradores.
En esta guía te enseño cómo hacerlo con LM Studio, que es probablemente la forma más simple de empezar. Yo lo he probado en un MacBook Air M2 con 8 GB de RAM y la conclusión es bastante clara: para tareas ligeras, la IA local ya es una realidad. Para tareas pesadas, todavía necesitas bastante más máquina.
Guía de IA local para principiantes

Lo primero que debes hacer es descargar LM Studio. Lo puedes hacer desde su web oficial. Una vez tengas el programa en tu ordenador, completa la instalación siguiendo los pasos según tu sistema operativo.
El programa para Mac pesa 1,5 GB aproximadamente, pero te recomiendo que dispongas de unos 30 GB libres, porque los modelos son los que pesan realmente. Si quieres probar varios, vas a necesitar espacio. Una vez hayas abierto LM Studio, vas a ver una interfaz muy similar a la de cualquier chatbot.
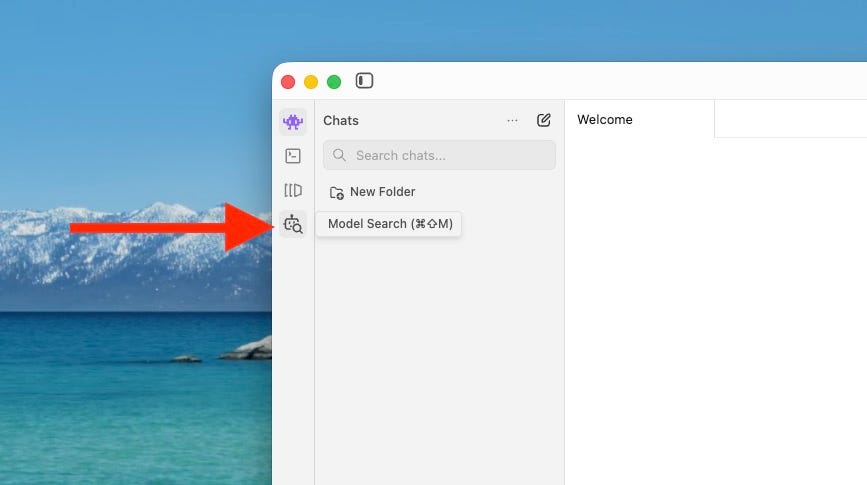
El problema es que no hay ningún modelo descargado. Sin el motor, el coche no se mueve. Así que presiona en el botón Model Search.
Al hacerlo, verás un montón de modelos de código abierto que puedes bajar. El más interesante ahora mismo es Gemma 4. Como yo tengo un Mac con 8 GB de RAM, Gemma 4 E4B es demasiado pesado. De momento, voy a descargar Gemma 4 E2B, que tiene menos parámetros. Más tarde probaré con el otro.
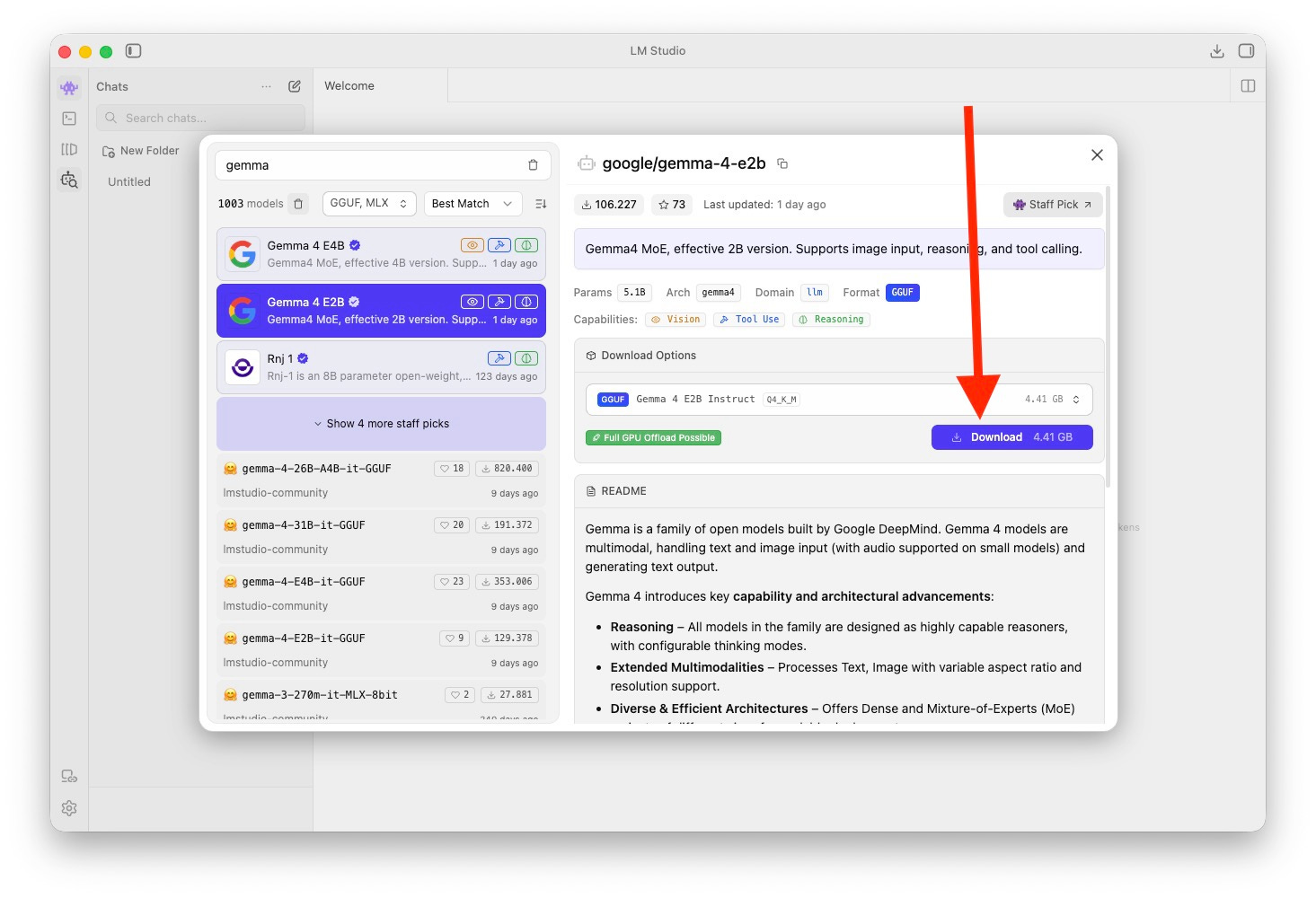
💡 Idea importante. No pierdas tiempo eligiendo un modelo ahora mismo. Puedes tener tantos como quieras, así que una vez completes esta guía, ve a por otro.
Cuando hayas descargado el modelo, cierra la ventana o presiona en el botón Use in New Chat. Esto iniciará un nuevo chat con el modelo cargado en la GPU de tu ordenador.
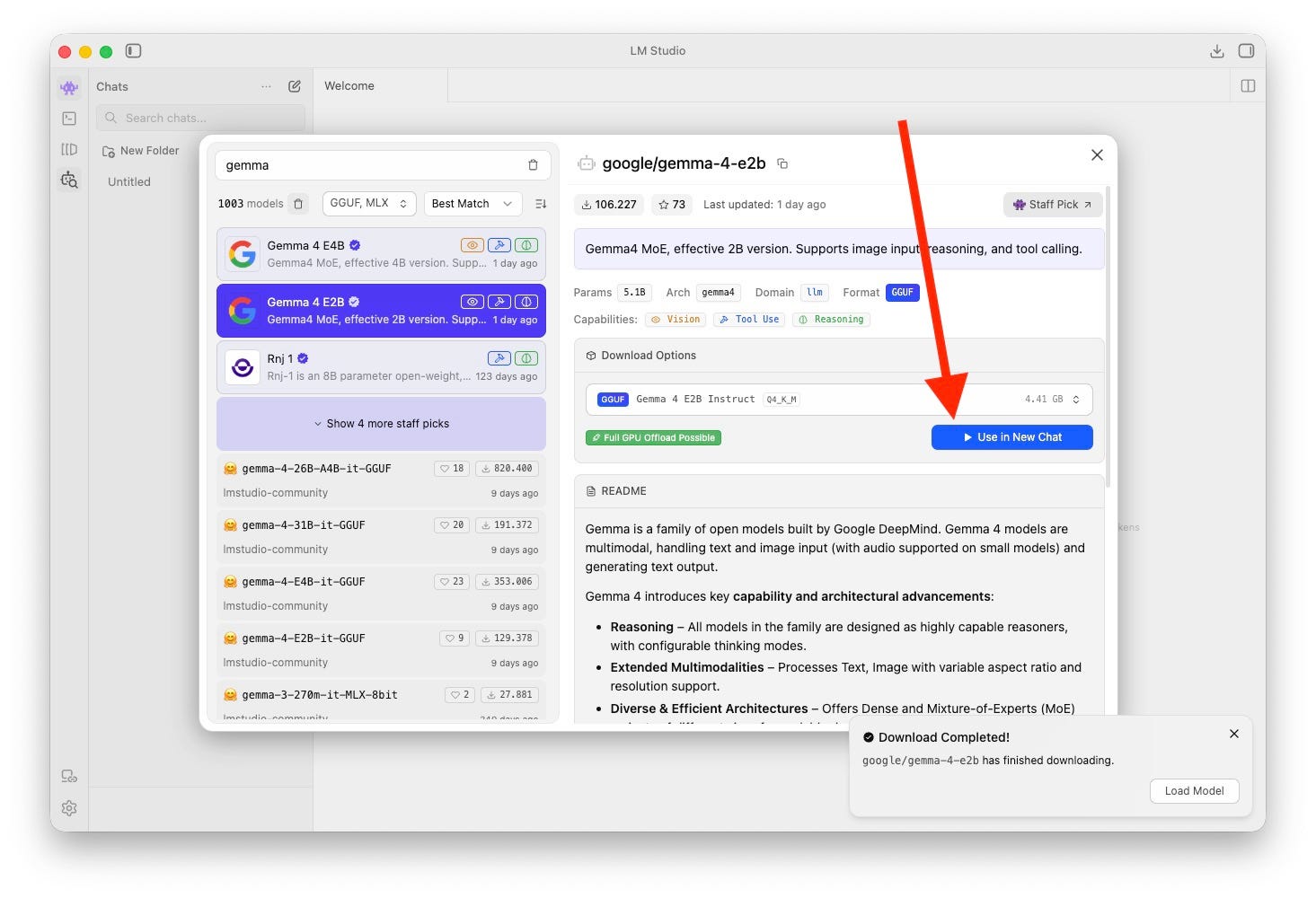
Recuerda que, si tienes más de un modelo descargado, en cada chat vas a poder elegir el que quieres usar para responder. Asimismo, en función del tipo de modelo, vas a ver unas funciones u otras. Por ejemplo, Gemma 4 E2B tiene la opción de activar el razonamiento o identificar elementos en una imagen. Por eso, aparecen las opciones Think y Vision.
Si dejamos a un lado los diferentes ajustes avanzados, en este punto ya lo tienes todo listo para empezar a trabajar con la IA en local gracias a LM Studio. La primera tarea que le voy a encargar al modelo es que me resuma el post oficial de Google sobre Gemma 4.
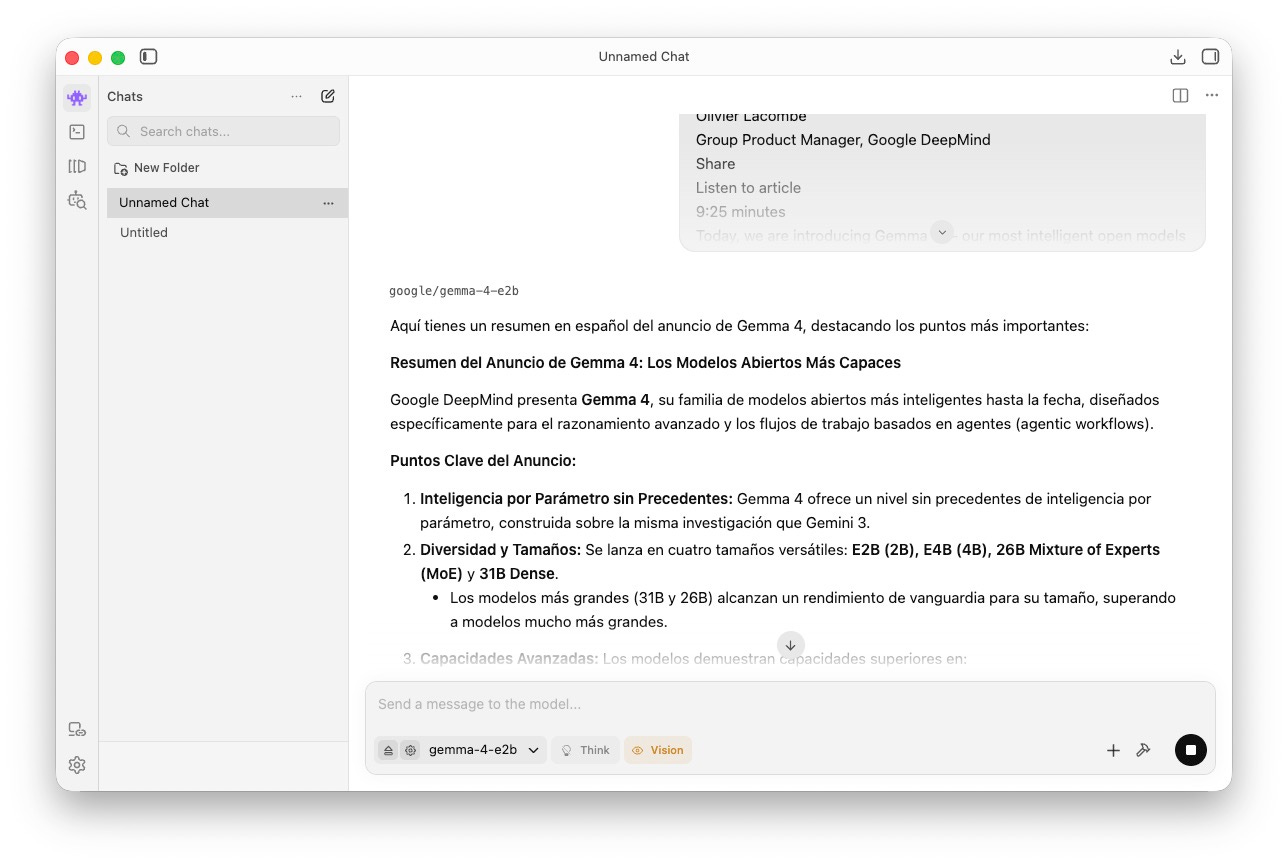
Como puedes ver en la imagen superior, el resultado para tareas sencillas es muy bueno. A mi juicio, se asemeja mucho a usar ChatGPT a principios de 2024, cuando los modelos eran mucho más sencillos.
Obviamente, no es oro todo lo que reluce.
Limitaciones que debes tener en cuenta
El matiz importante es este:
Que funcione bien no significa que compita con ChatGPT o Claude en capacidad general.
El modelo que he probado responde rápido, no ralentiza el sistema y resulta muy útil para tareas cerradas cuando ya le das el contexto o los datos. Pero sigue siendo un modelo pequeño, así que puede alucinar con facilidad y no conviene usarlo como fuente fiable para consultas importantes.
La promesa de la IA local es real, pero conviene ponerla en su sitio:
Funciona muy bien para tareas ligeras y con contexto previo.
Un modelo pequeño puede ser rápido, pero también alucina más.
Los modelos grandes exigen bastante más RAM, VRAM y paciencia.
En un portátil modesto, la experiencia deja de compensar mucho antes de lo que parece.
Hoy ya es útil para trabajo simple, pero no sustituye a los mejores modelos en la nube.
Preguntas frecuentes sobre IA local (FAQs)
¿Qué significa 2B, 4B o 20B?
Es una referencia aproximada al tamaño del modelo y la cantidad de parámetros. En general, cuanto más grande, más capaz, pero también más pesado y lento.
¿Cómo elijo un modelo sin complicarme?
Empieza por uno pequeño o mediano. Si tu prioridad es fluidez, mejor sacrificar capacidad que provocar bloqueos constantes en tu equipo.
¿Qué puede hacer bien un modelo pequeño?
Reformular texto, resumir, ordenar ideas, crear tablas o trabajar sobre información que tú ya le das.
¿Dónde fallan más estos modelos?
En preguntas abiertas, tareas complejas y consultas donde pueden inventarse datos si no les das contexto suficiente.
¿Cuánta memoria necesito?
En realidad, es difícil definir exactamente la memoria necesaria según el modelo, aunque esto puede servirte como referencia:
8 GB → Modelos pequeños, normalmente de 1B a 4B, y no siempre con margen cómodo.
16 GB → modelos de 4B a 8B con una experiencia bastante más razonable
24 GB → Puedes empezar a mover modelos de 8B a 12B con más soltura.
32 GB o más → Ya entras en terreno más serio para modelos mayores, aunque depende mucho de varios factores, como el sistema, el chip y si tienes gráfica dedicada y cuánta VRAM tiene.
Ayúdame a llegar a más gente
Si esta edición te ha resultado útil, haz que circule 🙃:
1️⃣ Compártela.
Envíala a alguien a quien pueda interesarle. Eso me ayuda más que cualquier algoritmo.
2️⃣ Dale un me gusta y deja un comentario.
Así la newsletter gana alcance y, además, me dejas tu punto de vista. También puedes responder a este correo.
3️⃣ Suscríbete gratis
Así no te pierdes las próximas ediciones con la IA que importa explicada en 5 minutos.

¡Nos vemos en la próxima!
Edgar.
Interesante, Edgar. Añado que LLM Studio tiene un servidor local, es decir, desde algún skill de Claude Code/Codex, la que sea, puedes hacer peticiones a tu LLM local gratis. Mi caso de uso más reciente: Opus 4.7 escribe muy mal en castellano, cuesta hasta leerlo a veces, así que he montado un /traducir que tira de mi IA en local Gemma 4. Una tontuzada, pero va de lujo.